AI SEO Agents operate through three autonomous pipelines that handle the complete content lifecycle — from research and writing to publishing and ongoing quality monitoring. Built on LangGraph's ReAct architecture and powered by Amazon Bedrock, each pipeline runs as serverless infrastructure on AWS, scaling automatically with your workload. Our agents have completed over 50,000 autonomous content jobs, maintaining a 97% success rate across all pipeline stages. This page explains how each pipeline works, what happens at every step, and how to customize agent behavior to match your content strategy. If you have not set up your account yet, start with the Quick Start Guide.
The Three Pipelines
The platform is organized into three distinct pipelines, each handling a different phase of the content lifecycle. They can run independently or be chained together for a fully automated publish-and-monitor workflow.
| Pipeline | Purpose | Trigger | Duration |
|---|---|---|---|
| Content Pipeline | Research, write, and store SEO-optimized articles | Manual or scheduled | 2–5 minutes |
| Publishing Pipeline | Score, enhance, and publish articles to WordPress | Manual or auto-publish | 3–8 minutes |
| Audit Pipeline | Crawl and analyze an entire WordPress site | Manual or weekly schedule | 1–3 minutes |
The Content Pipeline is where new articles are born. It takes a target keyword and produces a fully researched, SEO-optimized article stored in S3, ready for review or publishing. The Publishing Pipeline takes articles from S3 and handles scoring, quality gating, WordPress publishing, and post-publish verification. The Audit Pipeline crawls your live WordPress site to identify technical SEO issues across all existing pages and posts, generating a comprehensive report.

Content Pipeline
The Content Agent is an autonomous AI agent powered by Claude Sonnet 4.5 on Amazon Bedrock. It uses a ReAct (Reasoning + Acting) architecture built on LangChain's create_react_agent — the agent thinks through each step, selects and calls tools, observes the results, and decides what to do next. There is no fixed script; the agent adapts its approach based on what it discovers during research.
The agent has access to 6 tools in create mode:
- search_web — Searches the web for your target keyword using Firecrawl SERP API, returning top results with titles, URLs, and ranking positions.
- scrape_competitor — Extracts content and structure from top-ranking competitor pages as clean Markdown for analysis.
- generate_content — Writes article sections using Bedrock's Converse API with tone and keyword density control.
- save_artifact — Stores the finished article in S3 with metadata (word count, keyword, SEO score).
- read_artifact — Reads existing articles from S3 (used in enhance and optimize modes).
- validate_published_page — Runs browser-based SEO checks via Playwright with 14 verification points.
The Content Agent supports three modes: create (new article from scratch), enhance (improve an existing article's content quality and depth), and optimize (target a specific SEO score of 85+, with access to the score_article tool for before/after measurement). Enhance and optimize modes require an existing S3 article key.
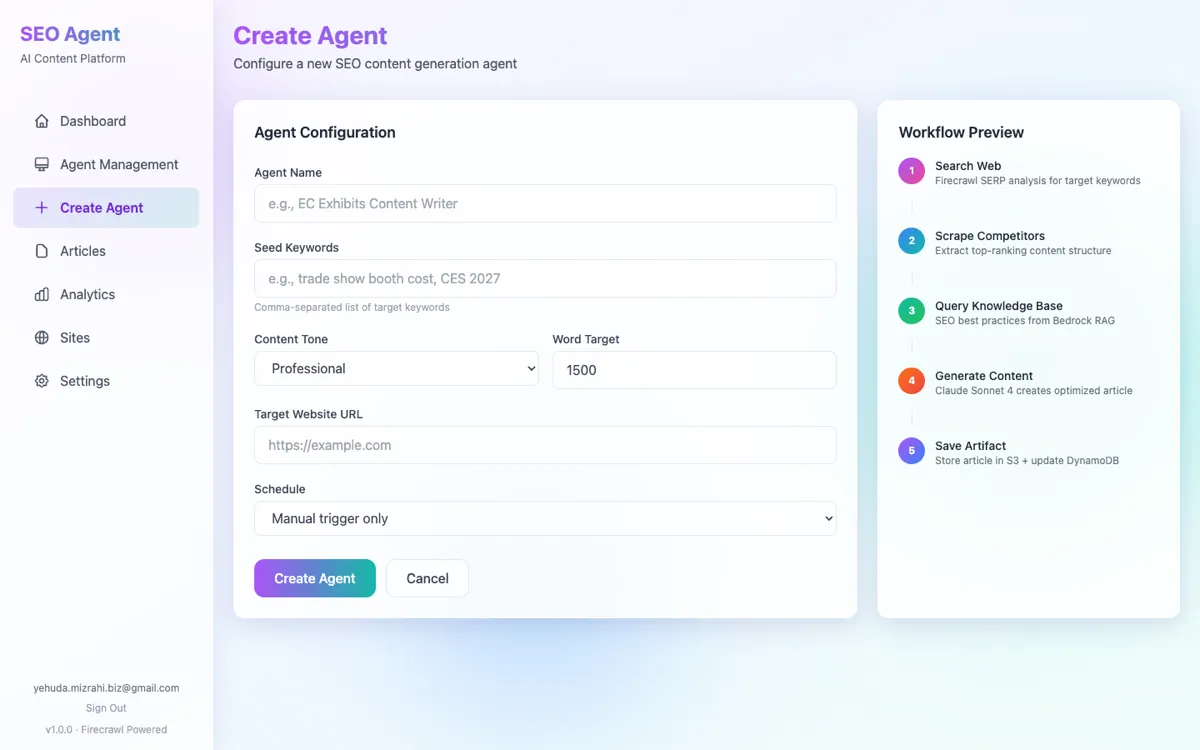
How the Content Agent Works
When you trigger a content job, the Content Agent follows a five-phase workflow. Each phase involves one or more tool calls, and the agent decides how to proceed based on the results it observes. The agent uses Claude Sonnet 4.5 for reasoning and content generation, and Firecrawl for all web research.
ANALYZE — Understand the competitive landscape
The agent calls search_web with your target keyword to retrieve the top 10 SERP results. It analyzes the titles, snippets, and URLs to understand what content formats are winning (guides, listicles, comparisons), identify common topics, and spot gaps in existing coverage.
RESEARCH — Deep-dive into top competitors
The agent calls scrape_competitor on the top 3 ranking pages, extracting their full content as Markdown. It analyzes heading structure, word count, topic coverage, keyword usage, and internal linking patterns. This competitive intelligence forms the foundation of the article outline.
PLAN — Build a detailed outline
Based on the research, the agent constructs an article outline with H2/H3 headings, target word counts per section, and internal linking opportunities. The outline aims to cover every topic the top competitors mention, plus 2–3 unique angles they miss.
WRITE — Generate content section by section
The agent calls generate_content for each section of the outline, passing the section title, target tone, word count, and focus keyword. Each section is generated independently, maintaining consistent style and keyword density (~1%) throughout the article. The final article is assembled from all sections.
SAVE — Store the finished article
The agent calls save_artifact to store the complete article as a Markdown file in S3, along with metadata including word count, keyword, creation timestamp, and an initial SEO score. The article is now available in your Articles tab for review, preview, or publishing.
The agent's final message in the dashboard is a short summary (~130 words) of what it did — not the article itself. The actual article (typically 2,000–3,000+ words) is saved to S3 via the save_artifact tool and is accessible from the Articles tab.
Publishing Pipeline
The Publisher Agent manages the full lifecycle of getting articles from S3 to WordPress. It is a separate autonomous agent, also powered by Claude Sonnet 4.5, with access to 10 tools spanning scoring, publishing, auditing, and post management. The Publisher Agent operates in three modes, each designed for a different phase of the content lifecycle.
| Mode | Behavior |
|---|---|
| enhance | Scores all articles for an agent using the 10-dimension SEO scorer. Queues enhancement (via the Content Agent) for any article scoring below 70 or under 1,500 words. This is a batch operation ideal for improving content quality across your entire library. |
| publish | Scores the article → runs a quality gate check → publishes to WordPress using Elementor or HTML layout → runs a full content audit on the live page → verifies with Playwright browser checks → goes live. If any step fails quality thresholds, the article is held for review. |
| audit | Audits live published pages using Playwright-based browser checks. Fixes metadata automatically for pages scoring 50–70. Unpublishes (reverts to draft) anything below 50. Queues content enhancement for pages that need deeper improvements. |
Articles are published using either the Elementor Builder (rich multi-section layout with FAQ toggle widgets, JSON-LD schema, author bios, full-width images, and CTA sections) or the HTML Template Builder (clean semantic HTML with auto-generated table of contents and author card). Both builders automatically source images using a 3-tier strategy: WordPress media library keyword search, recent WordPress uploads, and Unsplash stock photography as a fallback.
Audit Pipeline
The Audit Pipeline is an AWS Step Functions state machine that crawls your WordPress site and generates a comprehensive SEO report. Unlike the Content and Publishing pipelines (which use LangChain agents), the Audit Pipeline is a fixed four-step workflow that runs deterministically every time.
- 1Collect — Fetches all published pages and posts via the WordPress REST API, extracting titles, URLs, content, and metadata for each.
- 2Analyze — Runs each page through the SEO analyzer in parallel using a Step Functions Map state. Checks title length, meta description quality, heading structure, word count, internal/external links, and image alt text.
- 3Report — Aggregates all individual page scores into a comprehensive site-wide report, identifying the highest-impact issues. The report is stored in S3 as a JSON artifact with a presigned URL.
- 4Notify — Sends an SNS notification with the report summary, including the overall site score, number of issues found, and a link to the full report.
The Audit Pipeline can be triggered manually from the dashboard, via the API, or on a weekly schedule (every Monday at 3 AM UTC). It typically completes in 1–3 minutes depending on the number of pages on your site. For details on what the audit checks and how issues are scored, see Technical SEO Fixes.
Token Budget and Cost Control
Every agent invocation operates within a configurable token budget that controls both cost and runtime. The default budget is 200,000 tokens per job, which is sufficient for generating a 2,500-word article with full competitive research. Understanding the token budget helps you predict costs and optimize your workflow.
- Typical cost per article: $2–4 for a 2,000–3,000 word article including all research, planning, and generation steps. This covers both input tokens (prompts, tool results) and output tokens (agent reasoning, generated content).
- Token tracking: The
TokenBudgetCallbacktracks cumulative token usage across all turns. When the budget is reached, it raises aTokenBudgetExceededexception that the agent handles gracefully — saving any partial work and returning a summary of what was completed. - No runaway costs: The budget acts as a hard ceiling. Even if the agent enters a complex research loop, it cannot exceed the configured limit. Failed jobs due to token budget are marked with a
token_budget_exceededstatus so you can identify and retry them with a higher budget if needed. - Cost comparison: Traditional SEO content workflows using agencies or freelancers typically cost $200–500 per article. AI SEO Agents deliver comparable or better quality at roughly 1% of the cost.
For long-form articles (3,000+ words) or highly competitive keywords that require extensive research, consider increasing the token budget to 300,000 tokens. You can configure this per-agent in the agent settings.
Job Lifecycle
Every job follows a consistent status lifecycle, regardless of which pipeline it belongs to:
pending → processing → completed | failed- pending — Job created and queued for processing. The Lambda function has been invoked but the agent has not started yet.
- processing — Agent is actively working. Progress events stream via WebSocket, showing tool calls, token usage, and intermediate results.
- completed — Job finished successfully. Results (article, report, or publish confirmation) are available in the dashboard.
- failed — Job encountered an error. Check the error message in job details. Common causes: token budget exceeded, WordPress connection error, or Bedrock throttling.
Status transitions use DynamoDB conditional updates to prevent race conditions. A job can only move from pending → processing and from processing → completed/failed. Both completed and failed are terminal states.
Real-Time Progress Tracking
The dashboard receives real-time progress updates via WebSocket, powered by a two-layer architecture. The DynamoDBProgressCallback hooks into the LangChain agent lifecycle, capturing events on every tool start, tool completion, and LLM response. These events are appended to the job record in DynamoDB and simultaneously broadcast to all WebSocket subscribers watching that job.
Each progress event includes: the event type (tool_start, tool_end, llm_response), a human-readable description, the current turn number, cumulative token usage, and a timestamp. The dashboard renders these as a live activity feed, showing you exactly what the agent is doing at any moment — for example, "Scraping competitor: https://example.com/top-article" or "Generating section: Benefits of Custom Trade Show Booths".
The WebSocket connection uses JWT authentication (Cognito) and automatically reconnects with exponential backoff (1s → 30s) if disconnected. If WebSocket is unavailable (e.g., behind a corporate proxy that blocks WebSocket upgrades), the dashboard falls back to HTTP polling at 3-second intervals via the GET /dashboard/jobs/{id}/progress endpoint. Both methods deliver the same event data.
AI SEO Agent Workflow Customization
Agents are highly configurable. You can adjust the following settings per agent to match your content strategy, brand voice, and publishing cadence. All settings can be changed at any time from the Agents tab in the dashboard.
| Setting | Options | Default | Notes |
|---|---|---|---|
| Tone | Professional, Conversational, Technical, Persuasive | Professional | Controls the writing style of generated content. Professional works for most B2B content; Conversational is better for blogs and lifestyle content. |
| Word Target | 1,500–5,000 words | 2,000 | The target word count for generated articles. Higher targets produce more comprehensive content but consume more tokens. 1,500–3,000 is optimal for most keywords. |
| Schedule | Manual, Daily, Weekly | Manual | Manual means you trigger each job yourself. Daily and Weekly schedules automatically generate content for all configured keywords on the set frequency. |
| Target Site | Any connected WordPress site | Primary site | For multi-site setups, select which WordPress site this agent publishes to. Agents can only target one site at a time. |
| Auto-Publish | On / Off | Off | When enabled, the Publisher Agent automatically scores and publishes articles that pass the quality gate (score 70+). When off, articles are generated and stored in S3 for manual review. |
For programmatic workflow customization, including triggering jobs with custom parameters, batch operations, and integration with external CI/CD pipelines, see the API Reference. The POST /dashboard/jobs endpoint accepts all agent configuration overrides as request body parameters.
Related Documentation
- Quick Start Guide — Set up your account and launch your first agent in 5 minutes.
- Technical SEO Fixes — How agents score articles and fix SEO issues automatically.
- Features Overview — Explore the full range of platform capabilities.
- API Reference — Trigger and manage jobs programmatically.
- Webhook Setup — Get notified when jobs complete.
- Case Study: 500 Fixes Monthly — Real-world results from automated agent workflows.
AI SEO Agent Lifecycle Management
Every AI SEO agent you create in the platform follows a well-defined lifecycle from creation to retirement. Understanding this lifecycle helps you manage your agents effectively, predict costs, and ensure consistent content quality across your sites. The agent lifecycle is designed around the principle that agents should be long-lived, reusable resources that improve over time as you refine their configuration.
Creation and Configuration
You create an agent from the Agents tab by specifying a name, target keywords, writing tone, and word count target. The agent is assigned a unique agent_id in the format agent-{hex} and stored in DynamoDB. At this point, the agent is in active status but has not generated any content yet.
First Job Execution
When you trigger the agent's first job — either manually or via a scheduled trigger — the Content Pipeline creates a new job record with a pending status. The Lambda function is invoked asynchronously, and the job transitions to processing as the agent begins its research-and-write workflow. You can track progress in real time via the dashboard.
Content Library Growth
Over multiple job executions, the agent builds a library of articles in S3 organized by keyword. Each article is stored with metadata including word count, SEO score, creation date, and the agent ID that produced it. The Articles tab provides a unified view across all agents, with filtering and sorting by score, word count, or date.
Ongoing Optimization
As your content library grows, you can use the enhance and optimize modes to improve existing articles. The Publisher Agent's enhance mode automatically identifies articles scoring below 70 and queues them for improvement. The optimize mode targets a score of 85+ by iteratively measuring and improving specific SEO dimensions.
Pausing and Resuming
Agents can be paused from the Agents tab or via the API (PUT /dashboard/agents/{id} with status: "paused"). A paused agent retains all configuration and content history but will not execute scheduled jobs. Resume at any time to pick up where you left off. This is useful for seasonal campaigns or budget management.
Retirement
When an agent is no longer needed, soft-delete it via the dashboard or API. The agent's status changes to deleted, but all generated content remains in S3 and can still be accessed, published, or reassigned to other agents. Deletion is a logical operation that preserves your content investment.
Decision Trees and Agent Reasoning
Unlike traditional automation scripts that follow a fixed sequence of steps, AI SEO Agents use a ReAct (Reasoning + Acting) architecture that makes intelligent decisions at every turn. The agent observes tool results, reasons about what to do next, and adapts its approach dynamically. This section explains the key decision points in each pipeline and how the agent chooses between alternative paths.
Content Pipeline Decision Points
- Competitor selection: After retrieving SERP results, the agent selects which competitors to scrape based on content relevance, page authority signals, and content format diversity. It prioritizes pages that rank in positions 1-5 and avoids scraping pages with thin content or paywalls.
- Outline depth: The agent adjusts the number of H2/H3 sections based on competitor analysis. If top-ranking competitors average 8 H2 sections, the agent targets 9-10 to provide more comprehensive coverage. Word allocation per section is weighted by topic importance.
- Content gap identification: When the agent detects topics covered by multiple competitors but missing from its current outline, it adds new sections. Conversely, if a section topic has very thin competitor coverage, the agent treats it as a differentiation opportunity and allocates extra words.
- Quality threshold: Before saving the final article, the agent evaluates its own output against the target word count and keyword density. If a section falls short, the agent regenerates it with adjusted parameters rather than saving substandard content.
Publishing Pipeline Decision Points
- Score threshold gating: Articles scoring below 70 are held for enhancement rather than published. Articles between 70-84 may be published as drafts for manual review, depending on your auto-publish settings. Articles scoring 85+ proceed directly to live publication.
- Layout selection: The Publisher Agent chooses between Elementor Builder and HTML Template Builder based on the target site's configuration. Sites with Elementor active get rich multi-section layouts with FAQ toggles and schema markup. Non-Elementor sites receive clean semantic HTML with auto-generated table of contents.
- Post-publish audit response: After publishing, the agent runs a 14-point content audit on the live page. If the audit reveals issues (e.g., missing alt text on images, slow TTFB, or broken internal links), the agent either fixes them automatically or queues a manual review, depending on the issue severity.
- Unpublish decision: During audit mode, pages scoring below 50 are automatically unpublished (reverted to draft) to protect your site's overall SEO health. Pages scoring 50-70 receive targeted metadata fixes. This automated quality control prevents low-quality content from remaining live indefinitely.
Monitoring Workflows and Alerts
Effective SEO requires continuous monitoring, not just one-time content creation. AI SEO Agents provide multiple monitoring mechanisms that keep you informed about content performance, agent activity, and site health. The monitoring system is designed to surface actionable insights without overwhelming you with notifications.
| Monitoring Channel | What It Tracks | Frequency | Configuration |
|---|---|---|---|
| Dashboard Stats | Active agents, total articles, average SEO score, recent jobs | Real-time (WebSocket) | Always on — no configuration needed |
| Job Progress Feed | Per-job events: tool calls, token usage, status changes | Real-time (WebSocket + HTTP fallback) | Automatic for all running jobs |
| SNS Notifications | Audit report summaries, job completion alerts | Per-event | Configure SNS topic subscriptions (email, Slack, etc.) |
| Webhook Callbacks | Job completion, article scores, publish confirmations | Per-event | See Webhook Setup |
| Weekly Audit Reports | Full site SEO health assessment | Weekly (Monday 3 AM UTC) | Enable via EventBridge schedule in settings |
The dashboard provides at-a-glance monitoring through the stats grid, which shows your total active agents, total articles generated, average SEO score across all content, and the number of jobs completed in the current period. The activity chart visualizes job status distribution over time (30 or 90 day window), helping you identify trends in content production and quality. The category chart shows your top keywords by article volume, making it easy to spot over-invested or under-served topics.
Set up SNS email subscriptions for audit reports to receive weekly site health summaries without needing to log into the dashboard. Combine this with webhook callbacks to route alerts to Slack, PagerDuty, or your own monitoring system for a comprehensive observability pipeline.
Advanced Customization Options
Beyond the basic agent settings (tone, word target, schedule), the platform offers several advanced customization options that give you fine-grained control over agent behavior. These options are available through the API and are designed for teams that need to integrate AI SEO Agents into existing content workflows or enforce specific quality standards.
- Custom token budgets: Override the default 200,000 token budget per job. Lower budgets (100,000) work well for short-form content or simple keyword targets. Higher budgets (300,000–500,000) are recommended for long-form guides, highly competitive keywords, or optimize-mode jobs that require multiple scoring iterations.
- Duplicate detection control: By default, the Content Agent checks for existing articles targeting the same keyword before generating new content. Set
force: truein the job request to bypass the pre-flight slug-collision check and let the Agent re-attempt generation. Note:force: trueis a partial bypass — the Agent will run, but its output is only saved if it scores higher than any existing same-slug article (dedup-by-score protection prevents accidental quality regressions). To genuinely replace a higher-scoring article, delete the existing S3 object first (S3 versioning preserves it) or use anenhancejob on its s3_key instead. - Publish status override: Control whether auto-published articles go live immediately (
publish) or are held as WordPress drafts (draft) for final human review. The default isdraft, and many teams keep it this way even with auto-publish enabled, using WordPress's built-in editorial workflow for the final approval step. - Multi-site targeting: For agencies and enterprise teams managing multiple WordPress sites, each agent can target a specific connected site. The site registry supports unlimited sites with independent credential management. See Connecting Your Site for setup instructions.
- Scheduling granularity: Beyond the built-in daily and weekly schedules, you can trigger jobs programmatically on any schedule using the API and your own scheduler (cron, Airflow, GitHub Actions, etc.). The
POST /dashboard/jobsendpoint accepts all configuration parameters, making it easy to integrate with CI/CD pipelines. - Webhook integration: Configure webhooks to receive real-time notifications when jobs complete, articles are published, or audits finish. This enables you to build custom automation on top of the platform — for example, automatically sharing new articles on social media or triggering downstream analytics workflows.
When increasing token budgets beyond 300,000 tokens, monitor your Bedrock usage carefully. While the platform enforces hard ceilings to prevent runaway costs, very high budgets combined with complex keywords can result in agent invocations lasting 8-10 minutes and consuming $8-12 per job. Check your plan limits to ensure your usage tier supports the desired budget.
Pipeline Interaction Patterns
The three pipelines are designed to work together as a cohesive system, but they can also be used independently depending on your needs. Understanding how they interact helps you build efficient automated workflows that minimize manual intervention while maintaining quality standards.
- 1Create → Review → Publish (Manual): The most common pattern for teams new to the platform. The Content Pipeline generates articles, you review them in the Articles tab, and then manually trigger publishing for approved content. This pattern gives you full editorial control while automating the most time-consuming part of the process — research and writing.
- 2Create → Auto-Publish (Automated): For teams confident in their agent configuration, enable auto-publish to let the Publisher Agent automatically score and publish articles that pass the quality gate. This is ideal for high-volume content operations where you need to publish multiple articles per day across several keyword clusters.
- 3Create → Publish → Audit (Full Lifecycle): The most comprehensive pattern chains all three pipelines. Content is generated, automatically published, and then monitored by the Audit Pipeline. Low-scoring live pages are automatically fixed or unpublished, creating a self-correcting content system. This pattern is recommended for enterprise deployments with established quality baselines.
- 4Audit Only (Existing Content): If you already have content on your WordPress site, start with the Audit Pipeline to assess your current SEO health. The audit report identifies your highest-impact issues, which you can then address by creating new content or enhancing existing pages through the Content Pipeline.
Regardless of which pattern you choose, all pipelines share the same DynamoDB job tracking, WebSocket progress reporting, and S3 artifact storage. This unified infrastructure means you can switch between patterns at any time without migrating data or reconfiguring your setup. For more details on connecting these pipelines to external tools, explore the API Reference and Webhook Setup documentation.
About AI SEO Agents
Built on AWS with Claude AI, our platform automates SEO analysis, content generation, and WordPress publishing for sites worldwide. Trusted by agencies and businesses managing multi-site SEO at scale. See real results →